
Teknisk guide til podkastproduksjon del 2
Både Og Produksjonsbyrå v/ Hans Kristian Heide, Øystein Johnsen og Stian Letessier

Dette er del to av teknisk guide til podkastproduksjon som handler om etterarbeidet som gjøres etter opptak. Del en tar for seg det som skjer under opptaket. Den finner du her.
ETTER OPPTAK
Etter at opptakene er gjort, er det tid for etterarbeid. Det finnes mange ulike programmer som kan brukes, men prinsippene er de samme. I eksemplene som vises her er det Pro Tools som er brukt.
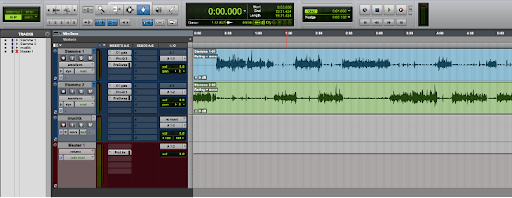
Her ser vi et enkelt grunnoppsett, med 2 stemmespor (mono), et musikkspor (stereo) og et master-spor (stereo).
Stemmesporene og musikksporet blir sendt til master-sporet, der de blir mikset sammen til ett stereosignal.
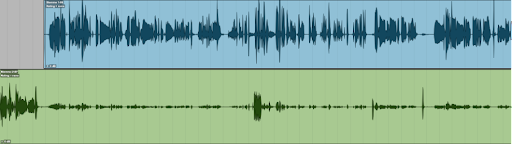
De to personene som har vært med i denne podkasten har sittet rett overfor hverandre i samme rom. Derfor ser vi at det er litt overhøring (lekkasje). Det vil si at litt av stemme 1, som snakket i mikrofon 1, har blitt fanget opp av mikrofon 2. I dette tilfellet er det ikke så mye at det er noe problem, men hvis man har mye overhøring, vil det gå utover lydkvaliteten og det høres amatørmessig ut. Da må man enten gjøre et nytt opptak med mikrofonene lenger unna hverandre, eller forsøke å fjerne overhøringen i etterkant, ved å klippe vekk lyd på sporet til personen som ikke snakker..
Det som er viktig å huske på når vi skal begynne å klippe, er at de to sporene ikke må forkyves i tid i forhold til hverandre. Da vil vi få en metallisk, ekko-aktig lyd som absolutt ikke er ønskelig.
Start-punkt

Når man skal lage et startpunkt, finner man ut hvor det skal være, klipper vekk det som er foran og lager en inn-fade. Hvis man ikke lager inn-fade kan man risikere å få et klikk i starten. Pass på å ikke klippe så tett inntil at starten på bokstaven blir borte.

Hvis vi zoomer inn på starten, ser vi at lydkurven der vi klippet ikke starter på null (på midtlinjen). Da vil vi sannsynligvis høre et klikk hver gang vi starter lydfilen.

Lag derfor en inn-fade for å unngå det.

Det samme gjelder på slutten av lydfiler, på alle klipp man gjør. Gjør det til en rutine å alltid lage inn- og ut-fade i alle lydfiler.
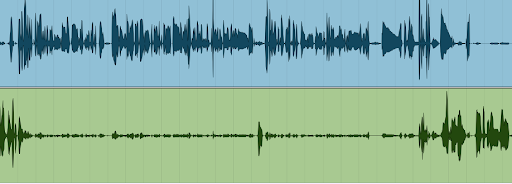
Å puste er det mest naturlige et menneske gjør. Pass på å ikke klippe midt i en pust, enten det er på slutten eller i starten av et klipp. Det høres ikke bra ut.
Hvis du ønsker å fjerne en pust midt inne i en lydfil fordi det f eks er en voldsom smattelyd i den, vil det som regel være best å beholde den naturlige avstanden. Altså klippe vekk pusten uten å skyve filene inntil hverandre etterpå.
Ønsker du å være litt «feinschmecker» finner du en annen pust, kopierer den, og erstatter den pusten du ville fjerne.
Hvis man skal klippe vekk en setning, fungerer det ofte greit å beholde pusten fra før ut-punktet. Hvis ikke det høres bra ut, kan man forsøke med pusten før inn-punktet, eventuelt fjerne hele pusten.
Det man vil oppleve i forbindelse med pusting, er at man starter litt på den neste bokstaven samtidig som man puster inn mens man snakker. Skal man si et ord som begynner på a, vil man åpne munnen samtidig som man puster, skal man si noe som starter med p, vil man lukke munnen på slutten av pusten.
Det er viktig å bruke ørene og gjøre det som høres best og mest naturlig ut.
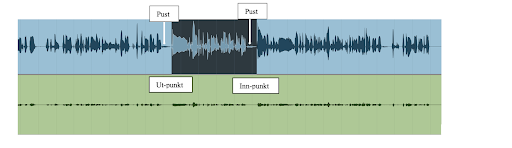
Her er det bare markert på det ene sporet for å vise, men husk at begge sporene må klippes likt så de ikke blir forskjøvet i forhold til hverandre.
Når man har fjernet det man ønsker, lager man en x-fade i skjøten for å unngå klikk. Det bør man, i likhet med inn- og ut-fade, gjøre til en rutine. Gjelder naturligvis for begge sporene, hvis man som i dette eksemplet har 2 spor.


LYDBEARBEIDING
For at resultatet skal bli så behagelig og tydelig som mulig å høre på, har vi flere verktøy vi kan bruke. Aller først må vi sørge for å ha god balanse. Det vil si at stemmene høres like høye ut. Jo nøyere man har vært med det under opptak, jo enklere blir etterarbeidet. Man kan til dels se nivåene på lydkurvene, men husk, som alltid, å bruke ørene.
Når vi hører på podkast er det som oftest noe støy omkring oss. Kanskje sitter man i bilen, går ute med øreplugger, eller hører på samtidig som man rydder på kjøkkenet. Da er det viktig at det ikke er for mye dynamikk i lyden. Med dynamikk menes det forskjellen på den laveste og den høyeste lydstyrken. Hvis det er mye dynamikk, vil man oppleve å måtte justere volumet opp og ned til stadighet for å ha et behagelig lyttevolum. Det blir man gjerne fort lei av, og da velger man heller å høre på noe annet. For å redusere/begrense dynamikken bruker vi kompressor og limiter.
Kompressor
En kompressor reduserer dynamikken ved å dempe de høyeste lydnivåene, og heve de laveste. Det gjør også at stemmene oppleves som nærmere, noe som stort sett er ønskelig. Brukes gjerne på hvert enkelt stemme-spor. Det er viktig å bruke kompressoren med forsiktighet. Hvis den brukes for hardt, vil det påvirke lyden negativt. Det betyr at hvis all lyden er langt over Threshold (forklaring under) vil det høres ut som om lyden «presses/pumpes», slik at feks. en pust høres like høy ut som pratingen. Man fjerner omtrent all dynamikken.
I tillegg til å følge med på meteret gjelder samme regel som alltid: bruk ørene. Programvare-kompressorer har gjerne mange forhåndsinnstillinger man kan velge, men det er veldig greit å forstå hvordan den virker. Derfor tar vi en liten gjennomgang av de viktigste funksjonene.

På venstre side ser vi Input, altså lydnivået inn i kompressoren. Samme nivået vises i vinduet mellom Threshold og Ratio. Videre ser vi at Threshold er satt til -20dB. Det betyr at når lyden passerer -20db i input blir den dempet. I dette tilfellet er Ratio satt til 2:1, som er ganske normalt for en stemme. Det betyr at hvis lydnivået går 2 dB over Threshold, øker det kun med 1dB. Knee er hvor hardt komprimeringen starter når nivået passerer Threshold.
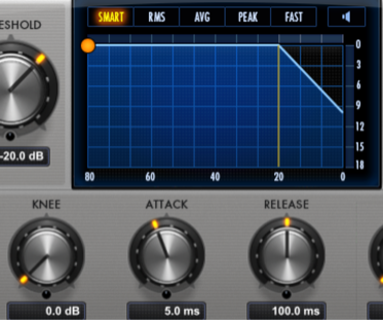
Her ser vi «hard knee» som betyr at komprimeringen starter umiddelbart.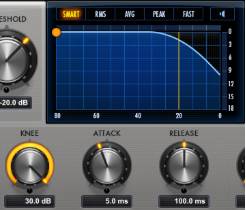
Med «soft knee» starter komprimeringen litt mere gradvis, og litt før signalet passerer Threshold.
Attack er tiden det tar fra signalet passerer Threshold til kompressoren begynner å jobbe.
Release er tiden det tar fra signalet går under Threshold til kompressoren slutter å jobbe.
Makeup er hvor mye det komprimerte signalet blir forsterket, før det går ut. Nivået på utsignalet ser vi helt til høyre, på Output.
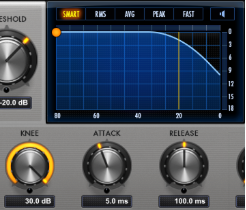
Hvor mye kompressoren jobber avhenger av hvordan vi stiller den inn og hvor dynamisk signalet er. Den trenger ikke å jobbe hele tiden. Ved «vanlig» snakking kan man som et utgangspunkt stille den inn slik at «gain reduction» ligger på ca 3-5 dB når signalet er sterkest.
EQ
For blant annet å øke taletydeligheten er EQ et godt verktøy. I vårt eksempel har vi plassert en Pro Q3 på hvert stemmespor.
Under ser vi eksempler på to forskjellige varianter.

Her ser vi hele frekvensspekteret «live» når vi spiler av stemmen. Da kan vi se om det er noen frekvenser som er veldig fremtredende og kan om ønskelig dempe dem, og omvendt dersom noen er veldig lave.
Her gjelder som alltid: bruk ørene.

Her har vi en annen variant. Dette er en 3-bånds equalizer. Det betyr at vi kan heve/senke i 3 forskjellige frekvensområder. Type er filtertype. 1 er et høypassfilter. Det betyr at frekvenser som ligger over valgt frekvens (i dette eksemplet 47 hz) passerer, mens frekvenser under blir dempet mer og mer fra 47Hz og nedover.
2 er et bell-filter med høy Q-verdi (99,9) som gir liten båndbredde. Gain er satt til 10,5 dB og frekvensen til 450 Hz. Det resulterer i at lyd rundt 450 Hz blir forsterket 10,5 dB og at de frekvensene som ligger tett inntil også blir litt forsterket.
3 er også et bell-filter med lav Q-verdi (1,8) som gir en høy båndbredde. Gain er satt til -12,3 dB og frekvens 4590Hz. Da vil 4590 Hz bli dempet 12,5 dB og frekvenser helt ned til 1 Khz og opp til 17 khz blir også gradvis dempet.

Make it stand out
Whatever it is, the way you tell your story online can make all the difference.
